Throughout April 2026, I saved more than 100 links. This proved quite challenging to organize and sort. It was a busy month for speech and audio, with plenty of releases for text-to-speech and conversational audio. I believe this is likely due to ICLR and ICASSP. I decided to focus primarily on TTS resources, which are covered in the nine highlights. This edition covers new open-source foundation models, multilingual scaling, streaming systems, and a cluster of papers exploring robustness, emotional expressiveness, and continuous modelling. Speech language models and full-duplex systems also feature prominently, alongside the usual mix of LLM research and engineering.
Highlights
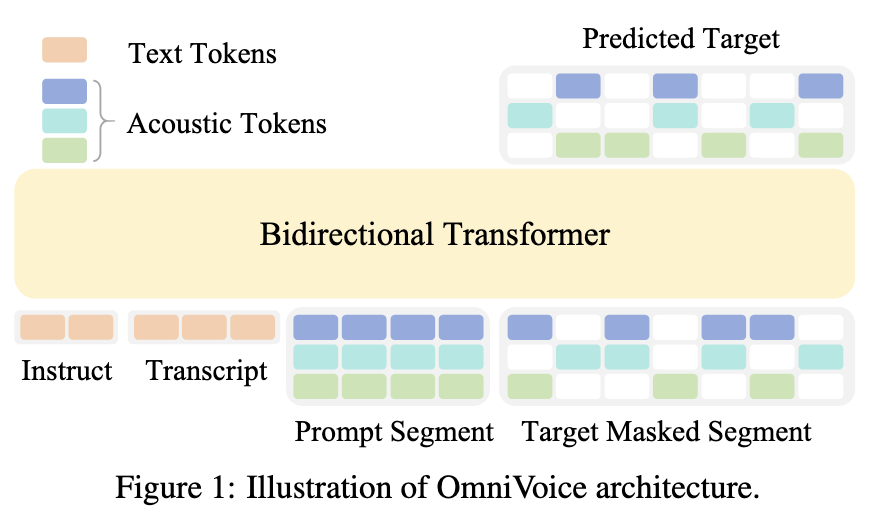
OmniVoice is a zero-shot TTS model covering more than 600 languages, and it is trained on 581k hours of open-source multilingual audio. The system uses a single-stage non-autoregressive diffusion-based model architecture. Specifically, OmniVoice is built on Qwen3-0.6B as the bidirectional transformer backbone (~0.8B total params) and on the Higgs-audio tokenizer (8-codebook acoustic tokens). Generation is done with a 32-step iterative unmasking loop.
There are two key contributions in this paper. The first is full-codebook random masking, where every token in the TxC matrix is independently masked, with 50% of the tokens used in the loss function. The second is the initialization of the LLM, which is based on pre-trained AR LLM weights (Qwen3-0.6B). According to the authors, initialization from an AR model helps improve intelligibility (measured through word error rate).
Weights are released under Apache 2.0, with code on GitHub (k2-fsa/OmniVoice ) and a live demo on HuggingFace Spaces .
Non-autoregressive (NAR) models generate all output tokens in parallel rather than one at a time like standard autoregressive (AR) models. The trade-off is between sequential dependencies and speed. In TTS, NAR architectures typically suffer from quality degradation compared to autoregressive counterparts, where AR architectures can be slow, but more stable.
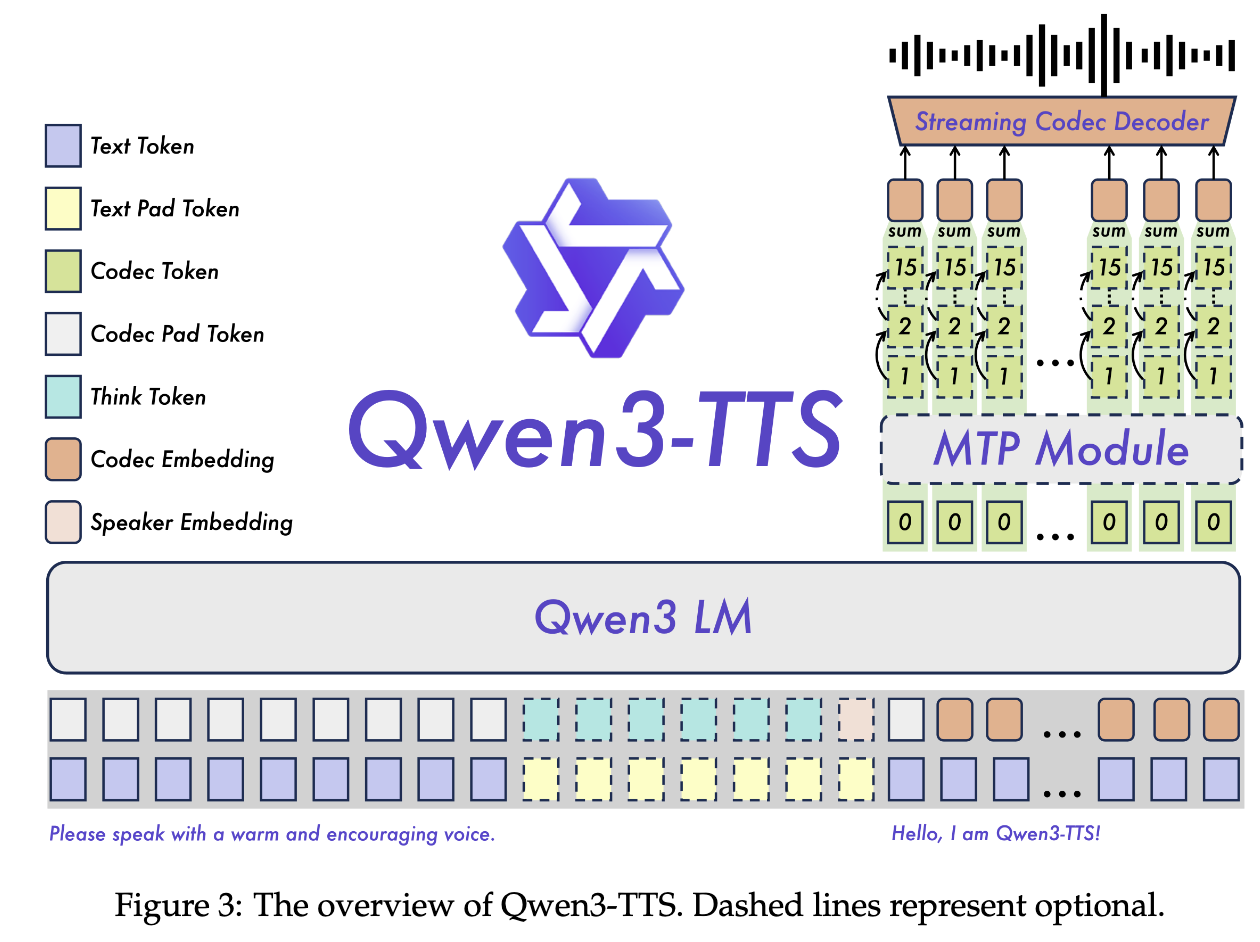
Alibaba’s Qwen team releases Qwen3-TTS, an open-source multilingual TTS series with 3-second voice cloning, description-based voice control, and streaming generation. Qwen3-TTS includes 0.6B and 1.7B models, with the series varying supported features.
The models are released with two specialised tokenizers: 1) Qwen-TTS-Tokenizer-25Hz, leveraging Qwen-Audio, this is a single-codebook representation focused on semantics with reconstruction via a diffusion transformer with block-wise flow-matching; and 2) Qwen-TTS-Tokenizer-12Hz, multi-codebook representation focusing on extreme bit-rate reduction, with reconstruction via a causal ConvNet decoder.
Qwen3-TTS is based on the Qwen3 LM family, interleaving text and audio tokens. Training follows a standard pipeline consisting of pre- and post-training, leveraging techniques such as Direct Preference Optimization (DPO) and Group Sequence Policy Optimization (GSPO).
The model series is released with code on GitHub .
DPO is a fine-tuning method that trains a model directly on preferred vs. rejected response pairs, bypassing the need for a separate reward model. See the DPO paper.
GSPO is a PPO-style reinforcement learning algorithm that computes importance ratios at the sequence level (length-normalized) rather than per-token, making training more stable by weighting all tokens in a response equally. See the GSPO paper.
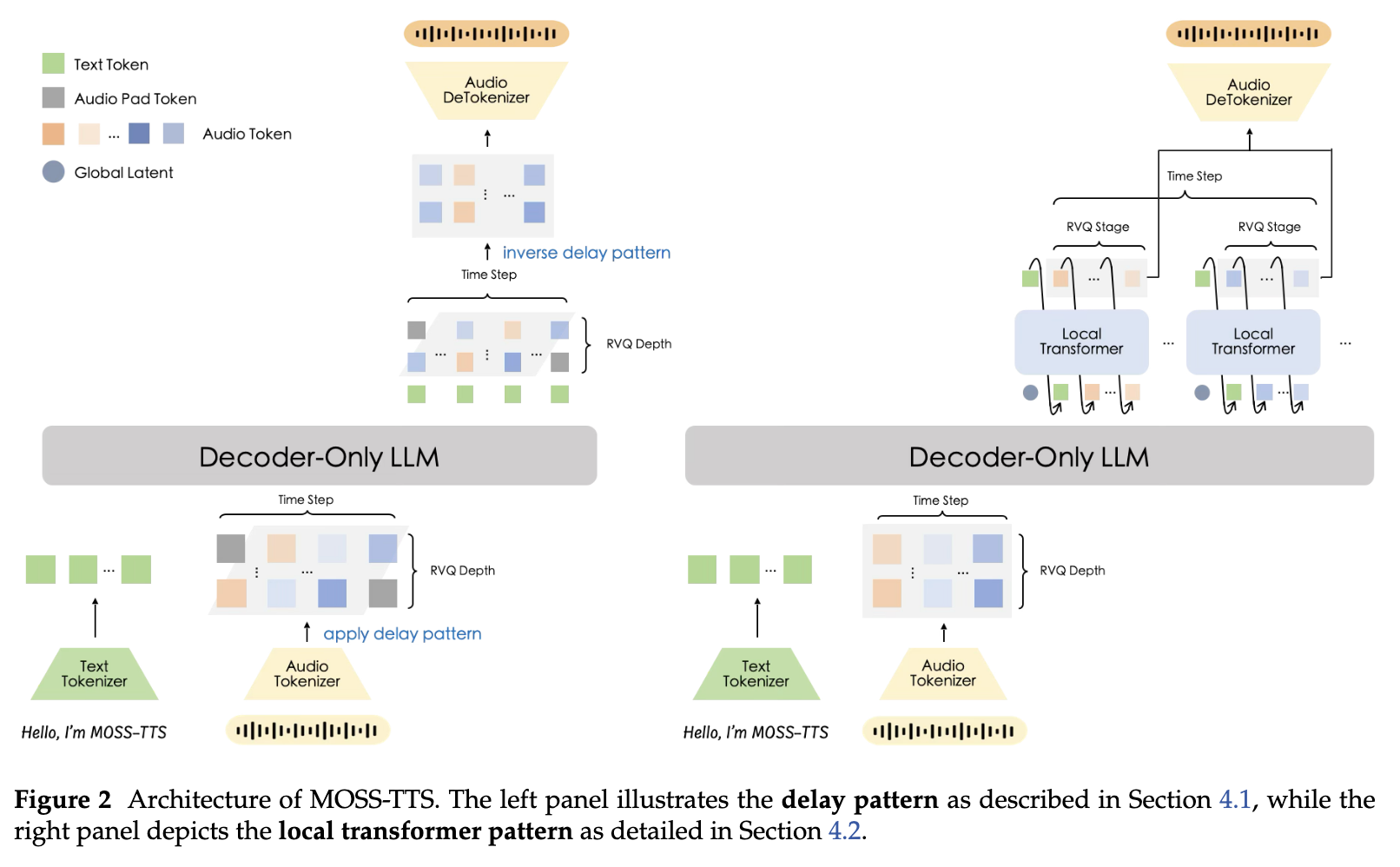
MOSS-TTS is an open-source speech generation foundation model. The technical report introduces the MOSS-Audio-Tokenizer and the MOSS-TTS system. The tokenizer is a 1.6B causal Transformer that compresses 24 kHz audio to 12.5 frames per second using a multicodebook representation with 32 RVQ layers. The model is trained on millions of hours of diverse audio, including speech, music, and noise.
The model backbone is a standard auto-regressive transformer language model with interleaved text and audio tokens. There are two approaches to modelling: 1) a delayed pattern strategy to RVQ tokenization, simpler to implement, but requiring N timesteps for N RVQ codebooks; and 2) a depth transformer to generate full RVQ codebooks from a global embedding at each time-step.
The report provides extensive details on data preparation for large-scale pre-training (preprocessing, filtering, synthesis) and comprehensive evaluations for the proposed audio tokenization method and TTS across various tasks.
Code and weights are publicly available .
In multi-codebook codec models, each audio frame is represented by K tokens — one per RVQ level. The delayed pattern extends these across time in a staircase pattern. See Figure 1 in the MusicGen paper. This turns an otherwise parallel K-token prediction into a standard left-to-right autoregressive stream without any architectural special-casing. The depth transformer, on the other hand, uses a small secondary transformer within each frame, modelling the conditional dependencies between codebook levels at that single timestep. See Figure 3 in the Moshi paper. Together they offer two complementary approaches: delay flattens the codebook dimension into the time axis; depth keeps it separate but handles it with a dedicated, lightweight model.
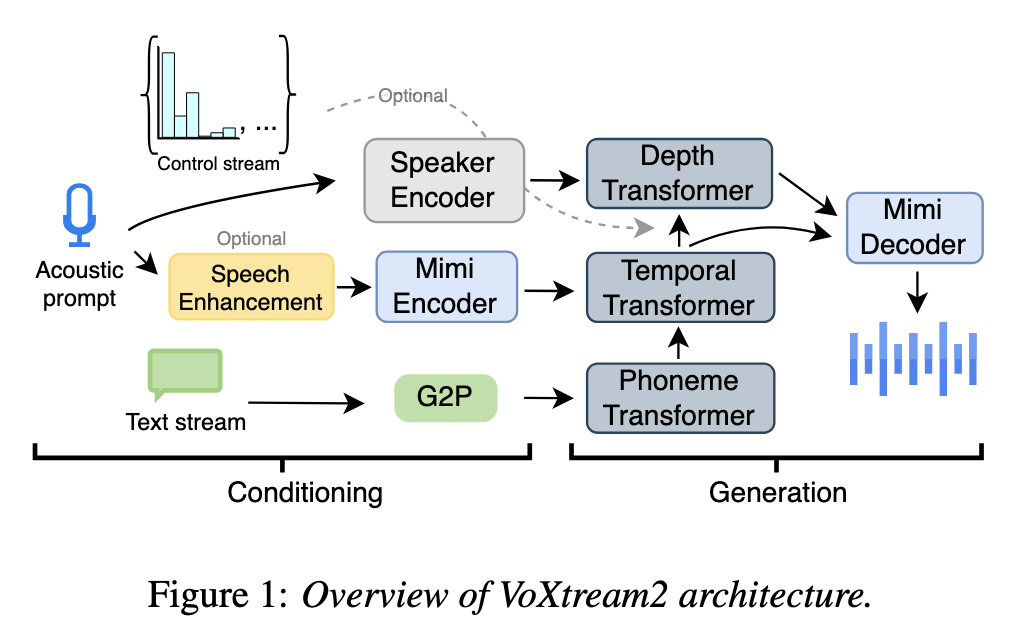
VoXtream2 is a zero-shot full-stream model where the rate can be updated mid-utterance on the fly, while the system continues generating audio with minimal delay as text arrives incrementally.
The VoXtream2 model is an autoregressive transformer that is conditioned on sequences of phonemes (given by a lexicon or a grapheme-to-phoneme component), and generates duration tokens enforcing a monotonic alignment between text and speech. The model consists of a primary temporal transformer, and a depth transformer to handle multi-codebook prediction. The codebooks are based on the Mimi tokenizer, introduced in the Moshi paper. The VoXtream2 model further uses classifier-free guidance (CFG) and masks text and audio conditioning signals during training with a probability of 10%. To adjust speaking rate dynamically during inference, the system manipulates the probability distributions of the duration states.
Model weights, code, a live demo , and a project page are all openly available.
“A full-stream TTS system is an architecture that operates entirely in streaming mode, accepting incrementally generated text tokens as input and producing small waveform chunks as output. A full-stream system begins generating speech before the full text is available, minimizing first packet latency.” (Section 2.2 of the paper).
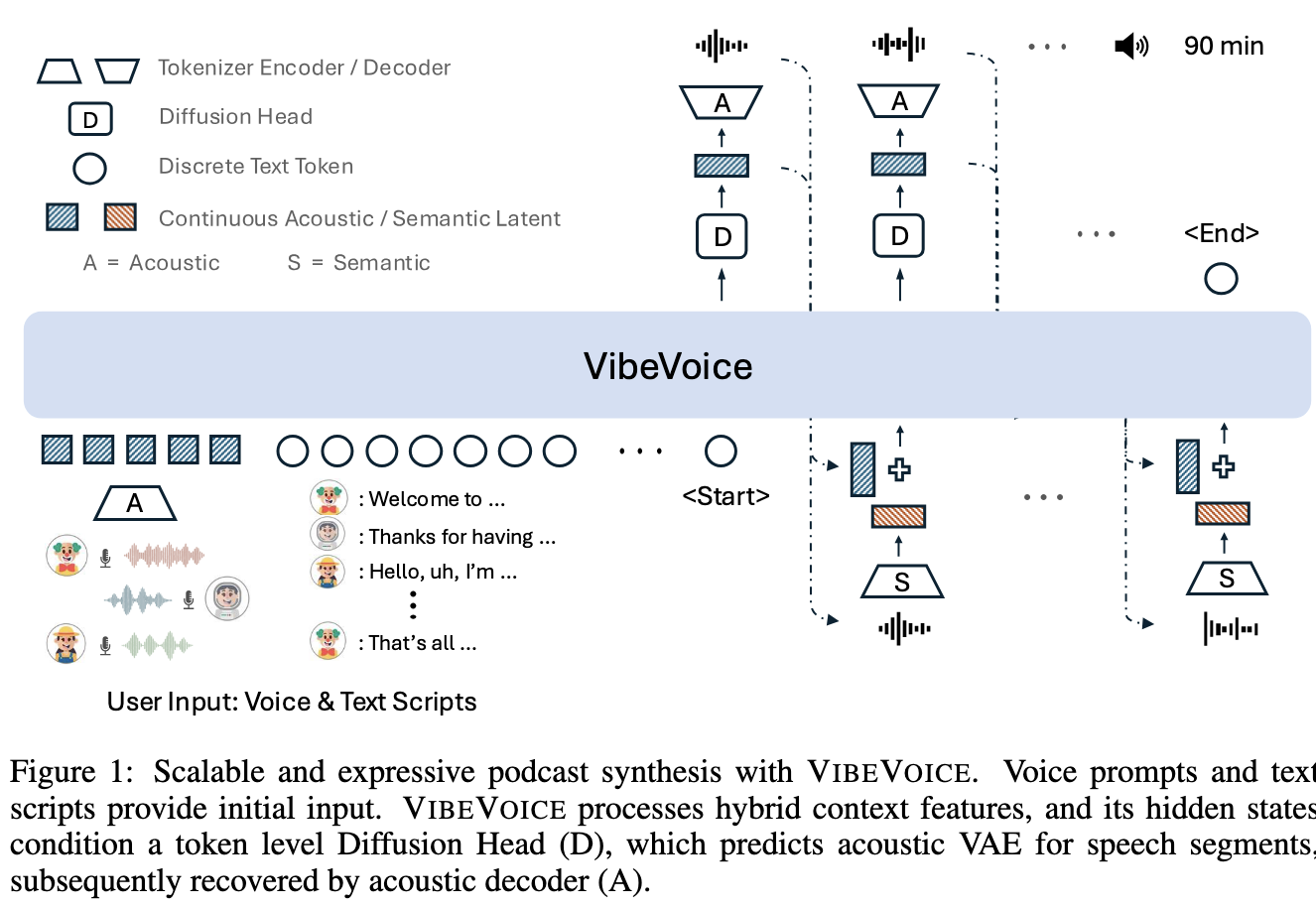
VibeVoice, an ICLR 2026 Oral from Microsoft, targets long-form multi-speaker podcast generation. This scenario can be challenging for speaker consistency across extended segments.
The paper describes two speech “tokenizers”, operating in continuous space. The Acoustic Tokenizer is based on Variational AutoEncoders (VAEs), specifically the σ-VAE variant. This tokenizer focuses on speech generation. The Semantic tokenizer is simpler and fully-deterministic, and focuses on speech understanding.
The VibeVoice model architecture uses an auto-regressive large language model with a diffusion head. It generates continuous acoustic representations at each timestep. The audio is then encoded with the semantic “tokenizer”, and both acoustic and semantic representations are combined through learnable projections. This is what the authors call “hybrid speech representations”, a mixture of both acoustic and semantic representations. Note that VibeVoice operates in a chunking-like format, with each timestep generating a chunk of audio that is concatenated to form the final rendered speech.
The system is open-source on GitHub , with the full technical report available on OpenReview .
Next-token diffusion combines the sequential generation of autoregressive language models with the continuous sampling of diffusion models. Language models predict one discrete token at a time from a fixed vocabulary. Next-token diffusion applies this to continuous latent spaces. Instead of predicting a discrete token via softmax, the model’s hidden state at each step is used to condition a lightweight diffusion head that iteratively generates a continuous latent vector. It is this continuous latent vector that is used to condition the language model in the next timestep.
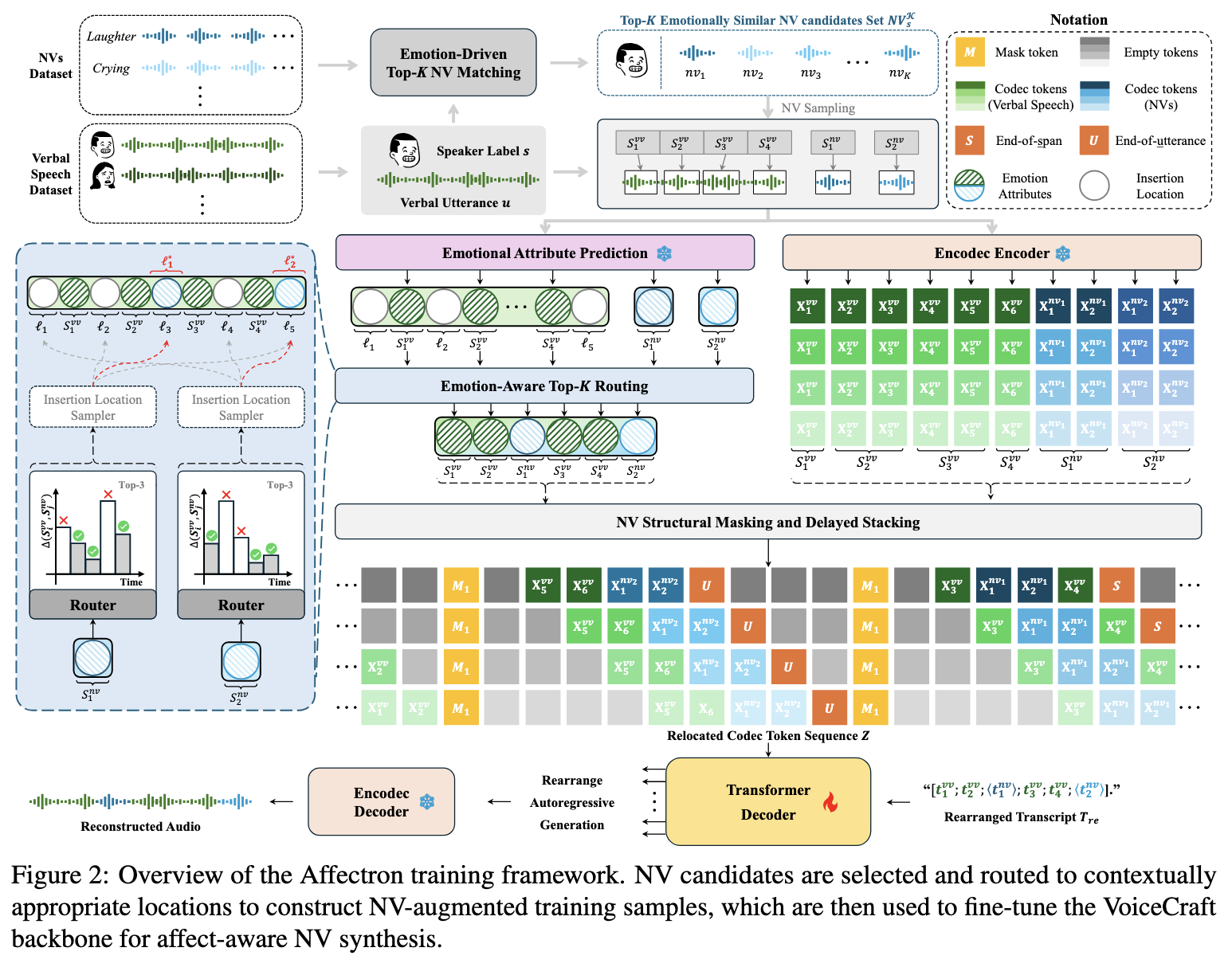
Affectron tackles the generation of nonverbal vocalizations like laughter, sighs, or hesitations, as part of emotional speech synthesis. Current systems rarely model NVs directly because labelled data is scarce and there is no obvious supervision signal for contextual alignment.
Affectron uses EnCodec, a multi-codebook codec, and VoiceCraft, a standard autoregressive language model generating codebooks with a delayed pattern. The main contribution is a data augmentation mechanism to inject nonverbal vocalizations onto a verbal dataset. The backbone language model is then fine-tuned on this augmented dataset.
The approach requires a dataset of nonverbal vocalizations and a dataset of verbal speech recordings annotated with overall emotion. The first step, Top-K NV Matching, addresses how to identify the top K candidates from the nonverbal dataset for each verbal utterance. The second step, Top-K Routing, decides where in the utterance to insert the selected NVs (e.g. before a sentence, mid-breath, at a clause boundary).
The investigation is based on the EARS corpus, which has limited speakers, and an overlap of speakers between the verbal and nonverbal datasets. Although it does show the feasibility of the mechanism, it is limited in that it doesn’t generalise easily to arbitrary verbal corpora where we don’t have matching NV recordings from the same speakers. This is acknowledged in Section 8 of the paper.
Code and a demo page are publicly available.
Nonverbal vocalizations (NVs) are vocal sounds produced by a speaker that carry affective or communicative meaning but contain no linguistic content — they are not words or phonemes. Examples include laughter, sighs, cries, gasps, filler sounds (like “uh”, “um”), chuckles, giggles, and snickers. They sit alongside speech to convey emotional state, hesitation, or social cues that words alone don’t capture.
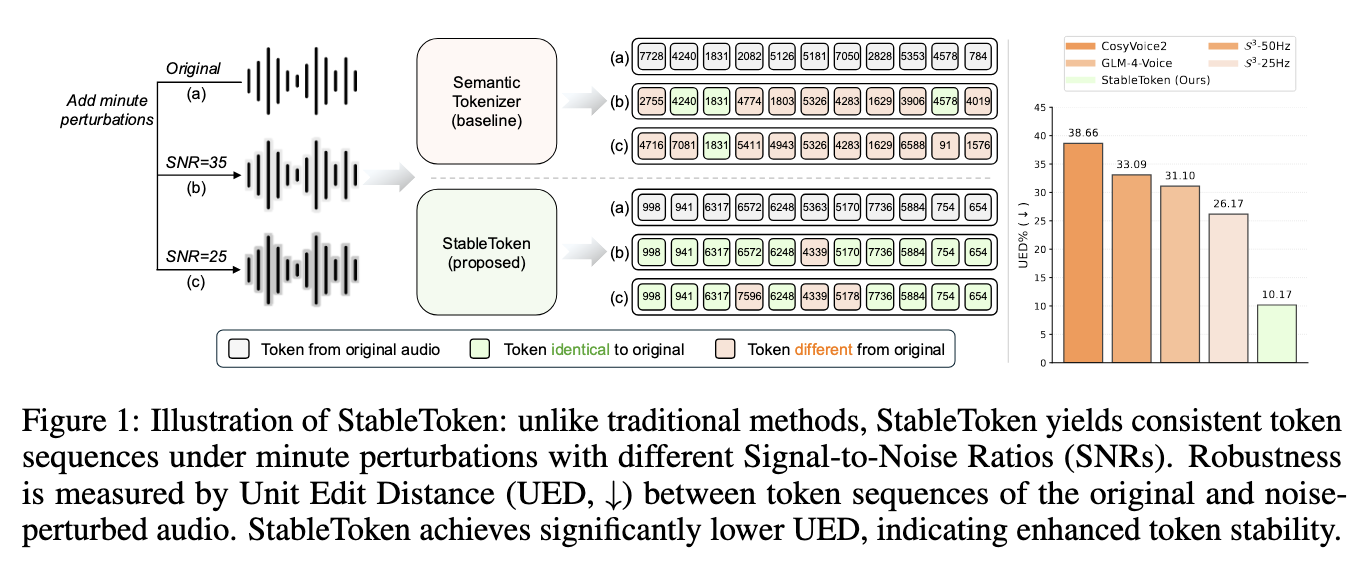
Standard semantic speech tokenizers can be sensitive to mild acoustic perturbations, leading to variable token sequences. StableToken is a speech tokenizer designed to achieve token consistency across variable signal-to-noise ratio. The model is built on top of Whisper-large-v3, which encodes a speech waveform into a sequence of hidden states. The whisper encoder is followed by average pooling to downsample the signal, and the Voting-LFQ module. Speech is reconstructed with the whisper decoder. StableToken is based on two dependent contributions: 1) a Voting-LFQ module (voting look-up-free quantizer), and 2) a noise-aware consensus training strategy.
The Voting-LFQ module runs multiple projection branches in parallel, with each branch providing a binary representation over the available tokens. Averaging over all branches gives a more reliable representation of the token sequence for the input sequence. At training time, the real-valued average is used directly by the model, whereas at inference time, the system performs a bit-wise majority vote.
This module is trained with a noise-aware consensus strategy. During each forward pass, a randomly selected minority of branches receives a noise-perturbed version of the hidden state, while the majority receive the clean version. A consensus loss then penalizes each branch’s deviation from the global average, thus ensuring that the token sequence is consistent even in the presence of noise.
For speech tokenization, Vector Quantization (VQ) maps a continuous representation to a nearest entry in a finite learned codebook, producing a single discrete token. Residual Vector Quantization (RVQ) extends this by stacking multiple VQ layers in sequence. While the first layer quantizes the input, the second quantizes the residual error left by the first, and so on. Look-Up Free Quantization (LFQ) is a different approach where each input is binarized dimension-by-dimension with a sign function. The binary code directly relates to an implicit codebook of size 2^d, where d is the hidden dimension size.
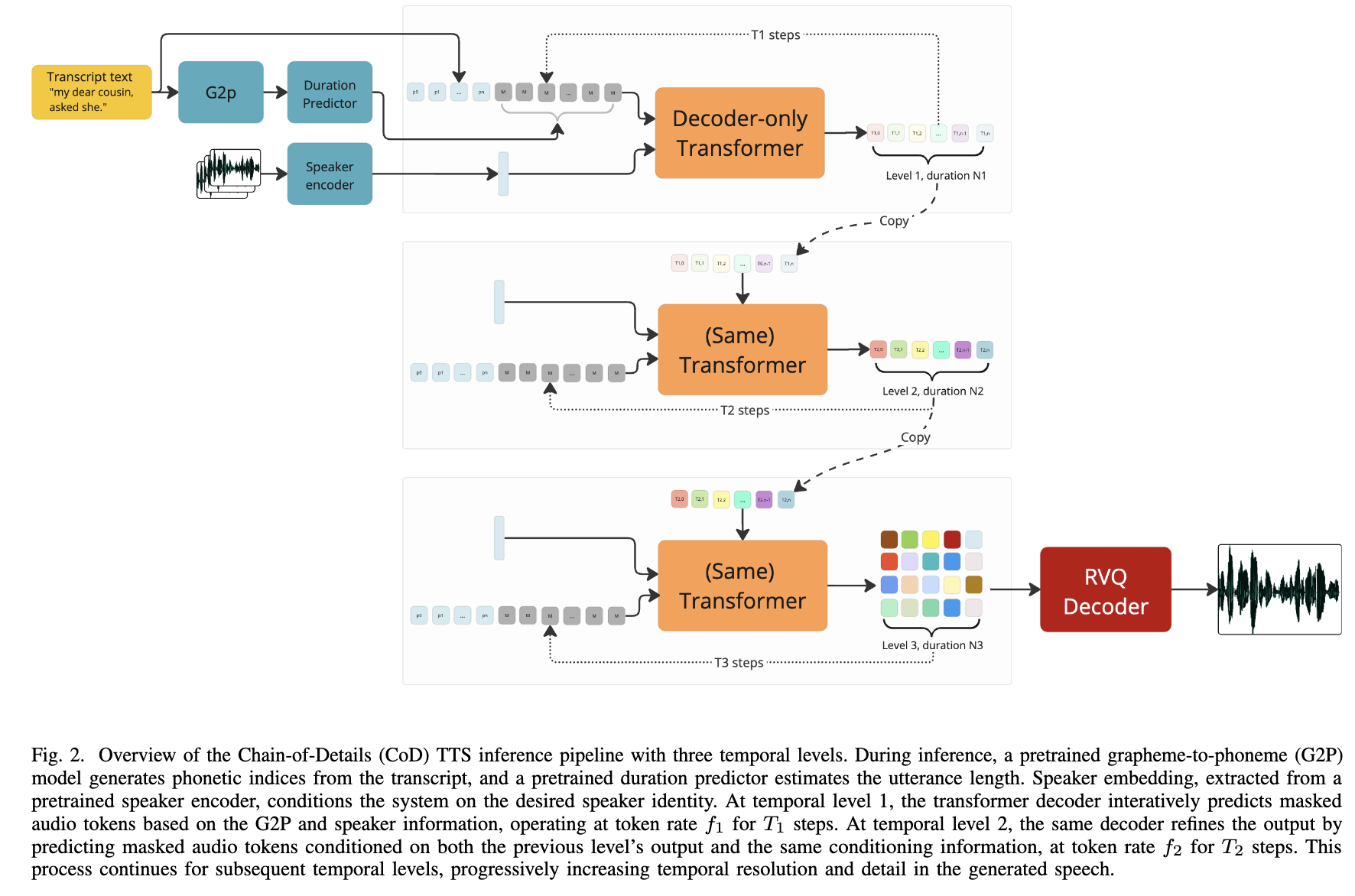
Chain-of-Details TTS is a non-autoregressive TTS system that reframes the standard coarse-to-fine generation paradigm along the temporal axis rather than the codebook depth axis.
Related work progressively refines RVQ quantization layers, which means such models iteratively decode along the codebook depth axis. CoD-TTS instead generates speech at increasing temporal resolutions, starting from a low token-rate sequence, then doubling the rate across successive levels to fill in finer acoustic detail. A single shared transformer decoder based on Llama with bidirectional attention handles all resolution levels. The system is conditioned at each stage on fixed signals like G2P phoneme sequences, speaker embedding, and a duration sequence. Within each level, generation is parallel: the decoder runs masked token modeling over a fixed number of steps, iteratively unmasking the most confident positions. The paper doesn’t seem to be claiming SOTA results, but rather competitive results on a 263M base model when compared to a 476M parameter two-stage baseline.
In masked token modeling, rather than generating tokens one at a time left-to-right, the model starts with a fully masked sequence and iteratively reveals tokens over a small fixed number of steps. At each step, the model predicts all masked positions simultaneously using bidirectional attention, where every position can attend to every other. The model then commits the most confident predictions and iterates on the remaining masked positions. A cosine schedule controls how many tokens are unmasked at each step. The number of decoding steps is fixed and tends to be small, so generation is much faster than autoregressive decoding. The main drawback is that the sequence length needs to be known upfront, so systems usually rely on separate duration models for speech generation.
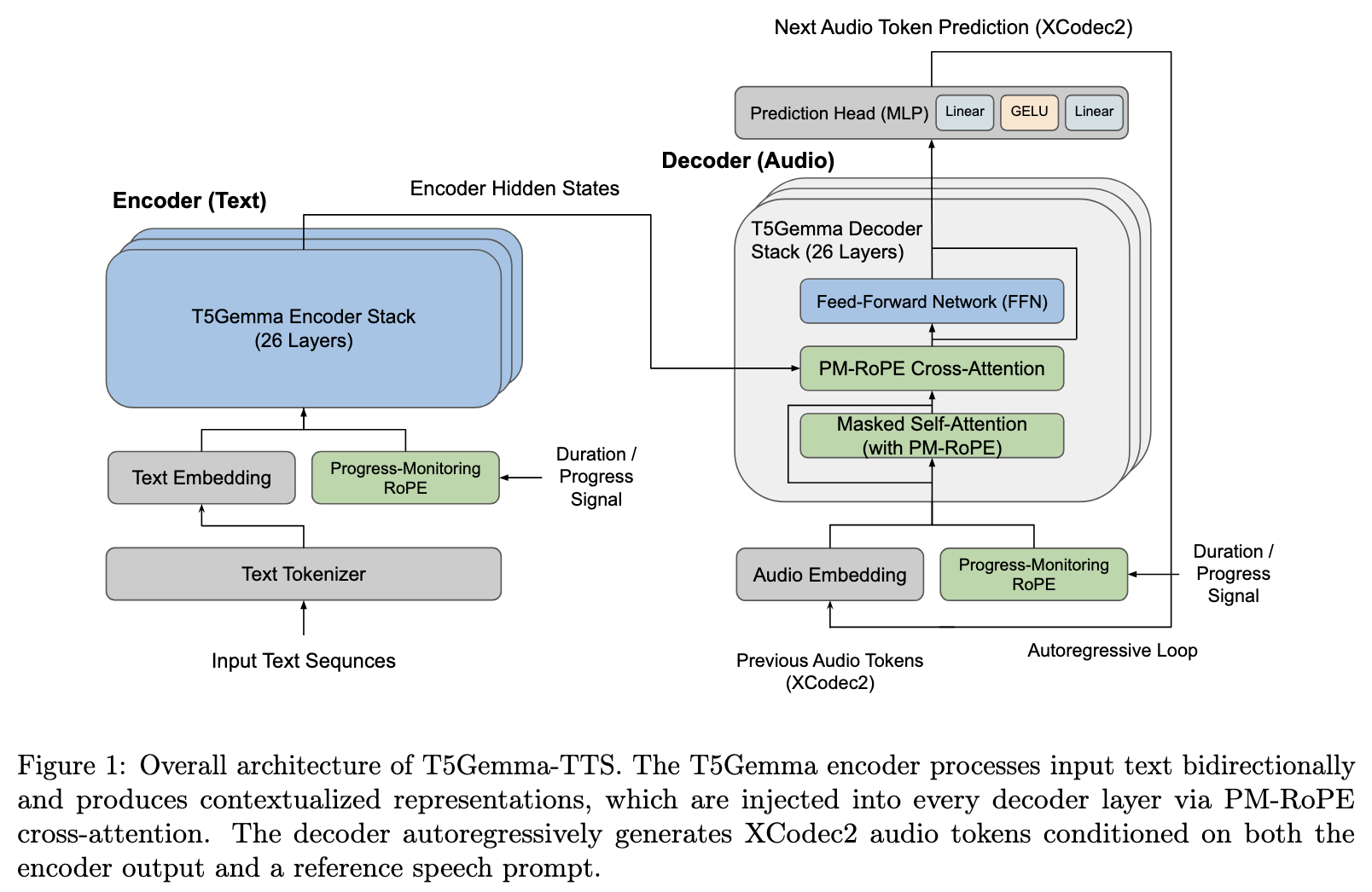
T5Gemma-TTS is a 4B parameter encoder-decoder text-to-speech model. The model is built on top of a 2B parameter T5 encoder and 2B parameter Gemma decoder. The model uses subword inputs rather than phoneme sequences, and it relies on the XCodec2 single-codebook tokenizer. The model applies Progress-Monitoring Rotary Position Embedding (PM-RoPE), proposed in the VoiceStar paper. The model is trained on English, Japanese, and Mandarin Chinese, and also evaluated on Korean, French, and German. This appears to be a straightforward model report with limited novelty. Perhaps the most interesting addition is the return to an encoder-decoder structure, and the validation of the PM-RoPE mechanism in a multilingual scenario.
Code and model weights are available on GitHub .
Rotary Position Embedding (RoPE) encodes positional information into attention queries and keys by rotating their vector representations by an angle proportional to a position index, such that the dot-product attention score between any query-key pair naturally reflects their relative distance. Progress-Monitoring RoPE (PM-RoPE) extends this by replacing raw token indices with normalized progress fractions, mapping each token’s position to a value proportional to how far through its respective sequence it sits. Cross-attention scores between a decoder query and an encoder key reflect alignment in progress rather than absolute position. This allows an autoregressive decoder to continuously track how far through the target output it has progressed relative to the input, enabling explicit length and duration control without requiring any supervised duration labels during training.
Research Papers
This is a list of research papers that I collected over the month of April 2026. I didn’t have time to go over them in detail. Summaries are mostly automatically-generated, but I reviewed and edited them briefly.
Speech & Audio
Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music | [Demo ] [Project ] Existing audio-language models struggle with long audio, multi-task generalisation, and reasoning across sound types. AF-Next from NVIDIA and UMD introduces a stronger foundation model backbone, improved long-audio handling, and timestamp-grounded understanding across speech, environmental sounds, and music. Three variants are released: instruct, captioner, and a chain-of-thought “think” version.
Enhancing Conversational TTS with Cascaded Prompting and ICL-Based Online Reinforcement Learning Conversational TTS requires prosody that adapts dynamically to multi-turn context, which single-pass generation struggles to capture. This paper introduces cascaded prompting: a two-stage pipeline combining autoregressive prosody prompting with diffusion-based acoustic prompting. It then trains the system with an ICL-based online RL objective that optimises perceptual quality without requiring reference audio.
MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control Transformer-based TTS encoders are computationally expensive at inference. MambaVoiceCloning replaces the encoder stack with Bi-Mamba and Expressive Mamba modules, reducing inference cost while a diffusion-based control module handles fine-grained acoustic variation. The authors demonstrate competitive voice cloning quality with significantly lower computational overhead than Transformer baselines.
Frame-Stacked Local Transformers For Efficient Multi-Codebook Speech Generation | [Model ] Multi-codebook speech generation requires predicting N codebook entries jointly at each timestep, introducing dependencies that strain standard autoregressive approaches. NVIDIA’s Magpie TTS addresses this with frame-stacked local Transformers that group codebook predictions spatially and operate on local attention windows, reducing quadratic attention cost. A 357M multilingual model is publicly available on Hugging Face.
Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-Duplex Speech Language Models | [Code ] [Project ] Training full-duplex speech LLMs requires high-quality multi-speaker conversational audio, which is a resource currently scarce and expensive to collect. Sommelier is an open scalable pipeline for extracting and cleaning such data from web speech, providing a reproducible data preparation recipe for the research community.
F-Actor: Controllable Conversational Behaviour in Full-Duplex Models | [Code ] Full-duplex spoken dialogue systems lack mechanisms for customising conversational behaviour at runtime, such as backchannels, interruptions, or response timing. F-Actor introduces a lightweight actor module that conditions the full-duplex model on behavioural style vectors, enabling runtime control over participation style without retraining the base model.
Latent Speech-Text Transformer | [Code ] Auto-regressive speech-text models are substantially less compute-efficient than text-only LLMs due to the much longer token sequences produced by speech codecs. Meta’s Latent Speech-Text Transformer (LST) addresses this by operating in a compressed latent space, reducing sequence length while preserving speech-text alignment. Code is available from Facebook Research.
In-Context Learning in Speech Language Models: Analyzing the Role of Acoustic Features, Linguistic Structure, and Induction Heads This paper examines how acoustic and linguistic features influence ICL performance for TTS in speech LMs, and identifies induction heads as a key component, providing interpretability insights relevant to more controllable speech generation.
Detecting Hallucinations in SpeechLLMs at Inference Time Using Attention Maps Hallucination detection methods developed for text LLMs do not directly capture audio-specific failure modes in speech LLMs, and existing approaches require gold-standard reference outputs. This paper proposes an inference-time detection method using attention map analysis that works without reference outputs and extends naturally to speech-specific hallucination patterns.
JUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion Video dubbing requires coordinated synthesis of speech and lip movements, which independent audio and video pipelines struggle to keep consistent. JUST-DUB-IT applies a joint audio-visual diffusion foundation model to dubbing, leveraging shared diffusion dynamics to maintain cross-modal temporal consistency throughout the generated output.
ICLAD: In-Context Learning with Comparison-Guidance for Audio Deepfake Detection Current audio deepfake detectors fail to generalise to in-the-wild conditions not seen during training. ICLAD introduces a comparison-guided ICL paradigm where the detector is conditioned at inference time on a small set of reference real and fake examples, significantly improving generalisation to novel deepfake types without retraining.
“Sorry, I Didn’t Catch That”: How Speech Models Miss What Matters Most Despite low aggregate WER on standard benchmarks, ASR systems frequently fail on short, high-stakes utterances. This paper studies the failure mode through U.S. street name transcription, showing that current models exhibit systematic errors on the specific lexical items that matter most in navigation context.
LLM & Training
LLMs Get Lost In Multi-Turn Conversation — ICLR 2026 Outstanding Paper When LLMs encounter underspecified or ambiguous instructions in early conversation turns, they tend to make assumptions and proceed. Then they fail to recover when those assumptions prove incorrect in later turns. The paper introduces a systematic evaluation framework for this failure mode and finds it affects all major frontier models, with direct implications for any interactive system where task specification evolves across a conversation.
MegaTrain: Full Precision Training of 100B+ Parameter LLMs on a Single GPU MegaTrain enables full-precision training of models with 100B+ parameters on a single GPU by treating the GPU as a transient compute engine and storing parameters and optimiser states in host (CPU) memory. Aggressive memory management and compute-memory overlap maintain GPU utilisation, making large-scale training accessible without multi-GPU clusters.
Neural Computers This paper proposes Neural Computers (NCs) as a paradigm that unifies computation, memory, and I/O of traditional computers in a learned runtime state, with the long-term goal of a Completely Neural Computer (CNC) capable of stable execution and programmability, a theoretical framing for learned general-purpose computation.
Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead In the standard two-stage post-training pipeline, high SFT scores do not reliably predict strong downstream RL performance for reasoning tasks. This paper documents the failure modes and proposes alternative metrics for evaluating SFT checkpoints before committing to costly RL training.
Agent Lightning: Train ANY AI Agents with Reinforcement Learning Agent Lightning is a flexible RL training framework for LLM-based agents that decouples the training loop from agent architecture and task specification, enabling RL-based training across diverse agent types without custom infrastructure per task.
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering A survey of the trend toward externalising capabilities from model weights into runtime components: memory stores, skill libraries, interaction protocols, and execution harnesses. The paper provides a unified taxonomy for this design space, which has become central to modern agentic systems.
Self-Improving Pretraining: Using Post-Trained Models to Pretrain Better Models Post-trained models generate improved synthetic pretraining data, which is then used to pretrain the next model iteration. The approach improves safety, factuality, and quality at the pretraining stage rather than relying solely on post-training corrections.
Diffusion-Pretrained Dense and Contextual Embeddings Introduces
pplx-embed, multilingual embedding models using a diffusion-pretrained LM backbone with bidirectional attention for web-scale retrieval. Multi-stage contrastive learning on the diffusion backbone yields strong performance on retrieval benchmarks.Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity Closed-source labs don’t publish parameter counts, and inference-cost estimates carry large uncertainty. This paper exploits an information-theoretic bound: storing F facts requires at minimum O(F) parameters, giving a tighter lower bound on model size from measurable factual capacity alone.
Black-Box On-Policy Distillation of Large Language Models Proposes Generative Adversarial Distillation (GAD), an on-policy knowledge distillation method that works without access to teacher model weights or logits. A discriminator trained on teacher vs. student outputs guides the student during generation, avoiding the off-policy distribution mismatch that limits standard sequence-level KD.
Multimodal
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM | [Code ] OmniVinci is an open-source omni-modal LLM for joint understanding of vision, audio, and language from NVIDIA Labs. The paper provides careful ablations on architecture design choices and data curation strategies for multi-modal pretraining.
Image Generators are Generalist Vision Learners | [Project ] Vision Banana from Google DeepMind demonstrates that image generation models trained purely on generative objectives develop strong zero-shot visual understanding — segmentation, depth estimation, surface normals — without discriminative fine-tuning, drawing a parallel to how LLMs develop emergent understanding from generative pretraining.
Creating ConLangs to Probe the Metalinguistic Grammatical Knowledge of LLMs | [Code ] [Project ] The paper uses LLMs to construct synthetic languages (ConLangs) with phonology, morphology, syntax, and orthography. The resulting ConLangs serve as a benchmark for probing metalinguistic knowledge under novel grammar conditions that models could not have encountered during training.
Also Worth a Look
This is a list of random links and resources that I collected over the month of April 2026. Most of them just seem like interesting things to bookmark, with the thought that I would review them at some point in the future.
TTS & Speech
- Gemini 3.1 Flash TTS : Google’s next-generation expressive TTS model, now available via the Gemini API (developer docs ).
- Soniox Text-to-Speech : New commercial TTS API covering 60+ languages with emphasis on alphanumeric pronunciation, language switching, and ultra-low-latency streaming.
- KittenTTS : A state-of-the-art English TTS model under 25MB.
- tiny-tts : An English TTS model with only 1M parameters.
- MOSS-TTS-Nano : The distilled edge variant of the MOSS-TTS family, available on ModelScope.
- KRAFTON/Raon-Speech-9B : A 9B multilingual any-to-any speech model from KRAFTON with voice cloning and multi-task capabilities.
- Text to Speech Leaderboard : Artificial Analysis’s open-weights TTS leaderboard with blind preference comparisons across models and providers.
- Full-Duplex-Bench-v3 : A benchmark for tool-using full-duplex voice agents evaluated under real-world disfluency using real human speech recordings, from NTU and NVIDIA.
- Seeduplex : ByteDance’s native full-duplex speech LLM, covering attentive listening and robust interference suppression.
- smol-audio : Practical, Colab-friendly notebooks for fine-tuning and running audio AI models.
- Evaluating Phonon : Evaluation of Phonon, an on-device TTS system with 100M parameters based on continuous audio language models.
General ML & Engineering
- DeepSeek V4 Preview Release : DeepSeek’s V4 model launch featuring 1M context length, with open weights and a technical report .
- Muse Spark: Scaling Towards Personal Superintelligence : Meta Superintelligence Labs’ first model: a natively multimodal reasoning model with tool use, visual chain of thought, and multi-agent orchestration.
- NVIDIA Nemotron 3 Nano Omni : NVIDIA’s open omni-modal reasoning model (30B/A3B MoE) unifying vision, audio, and language for agentic workflows; weights on Hugging Face .
- Claude Code Unpacked : The Claude Code agent loop, 50+ tools, and multi-agent orchestration mapped from source.
- Frontier Model Training Methodologies : Comparative breakdown of training recipes across seven open-weight frontier models including SmolLM3, Kimi K2, and DeepSeek-R1.
- Microsoft MAI Models : Microsoft announces three new MAI models available through Azure AI Foundry.
- Qwen 3.5 Omni and Qwen 3.6 : Alibaba’s latest Qwen model releases; Qwen3.6 local setup documented via Unsloth .
- Parlor : On-device, real-time multimodal AI for voice and vision conversations powered by Gemma 4 and Kokoro TTS.
- Running Gemma 4 Locally with LM Studio CLI & Claude Code : Practical guide for local Gemma 4 26B inference on macOS using the new LM Studio headless CLI.
- How We Broke Top AI Agent Benchmarks : Berkeley RDI on systematic vulnerabilities in major agent benchmarks and what the field needs to fix.
- ART: Agent Reinforcement Trainer : Open-source framework for training multi-step agents on real-world tasks using GRPO.
- Rowboat : Open-source AI coworker with persistent memory.
- agent-skills : Production-grade engineering skill definitions for AI coding agents.
- Feynman : Open-source AI research agent that reads papers, searches the web, runs experiments, and cites every claim, running locally.
- The Computer Always Wins : Sample pages from an MIT Press book teaching algorithms through board and word games.
- heretic / gemma4-heretical : Tools for removing safety fine-tuning from open-weight models; gemma4-heretical packages an abliterated Gemma 4 31B for Ollama and MLX with a corrected chat template.
- OpenMythos : A theoretical reconstruction of the Claude Mythos architecture built from published research literature.
- Mvidia : An educational browser game where you progressively learn how GPUs and digital hardware work by building circuits from low-level components.