This March 2026 edition of Clippings covers a busy month in speech and audio AI, with launches of new TTS models and evaluation frameworks alongside the usual mix of LLM engineering guides and research.
Highlights
Google’s Gemini 3.1 Flash Live is described as a low-latency streaming audio model that handles natural conversation. The model is marketed for interactive voice applications — live calls, voice assistants, and real-time transcription — with a focus on reliability and naturalness rather than raw capability alone. The post is light on architectural details, but the model card suggests that this model shares an architecture with Gemini 3 Pro , which is a sparse mixture-of-experts (MoE) transformer-based model.
Sparse MoE models activate a subset of model parameters per input token by learning to dynamically route tokens to a subset of parameters (experts); this allows them to decouple total model capacity from computation and serving cost per token.



Research Papers
Speech & Audio
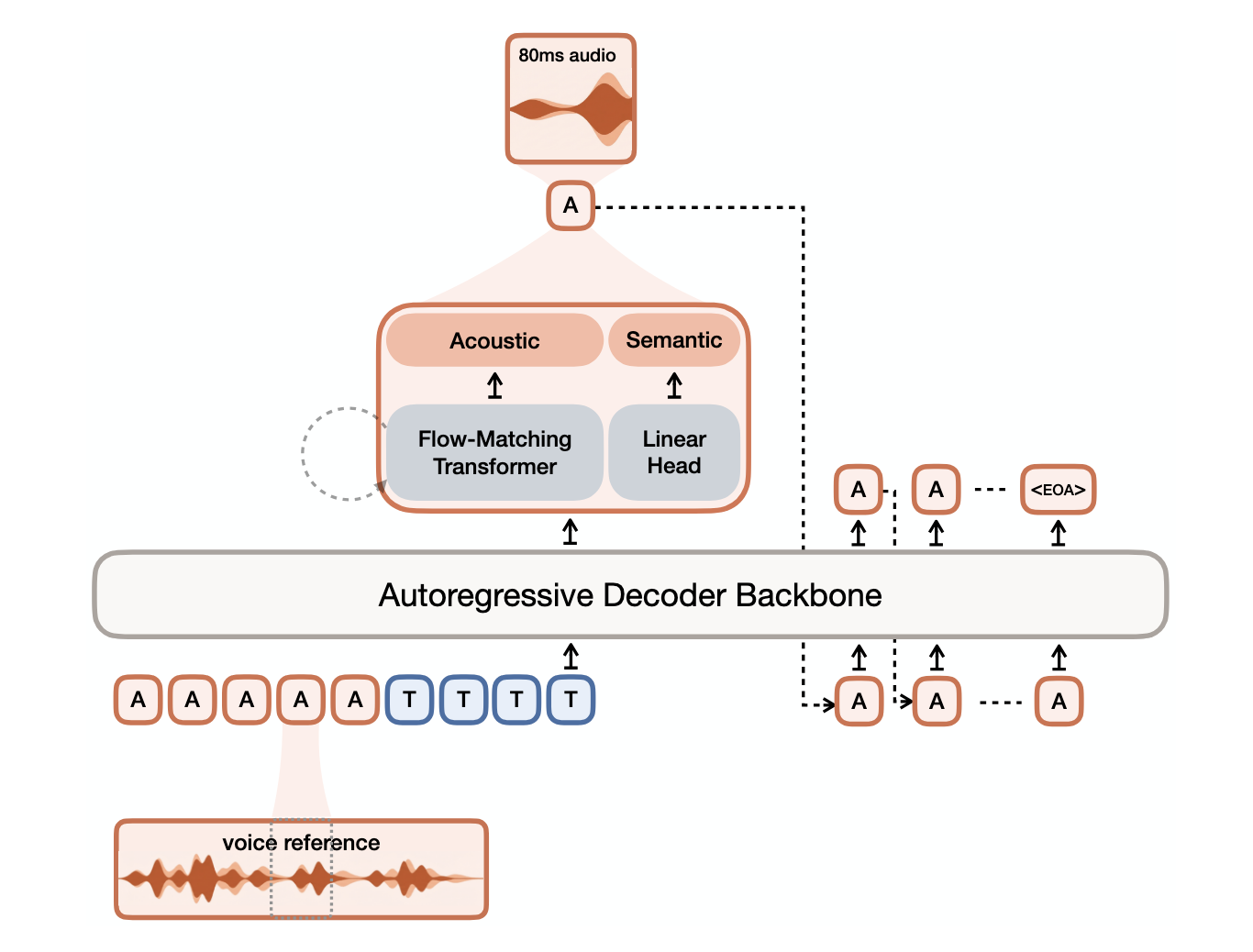
- VoXtream2: Full-stream TTS with Dynamic Speaking Rate Control — Full-stream TTS systems must begin speaking before the full input text is available, but existing approaches lose controllability once streaming has started. VoXtream2 introduces dynamic speaking-rate control that can be updated mid-utterance on the fly, responding to incremental text input. This makes it more practical for interactive dialogue systems where latency and real-time adaptability both matter.
- VoiceSculptor: Your Voice, Designed By You — Open-source TTS systems have lagged behind commercial ones in offering fine-grained, instruction-following control over speech attributes. VoiceSculptor bridges this gap with a unified system that accepts natural-language instructions to simultaneously control pitch, speaking rate, age, emotion, and style — without requiring structured parameter inputs. It’s notable as an open-source system that attempts to match the expressiveness typically found only in proprietary products.
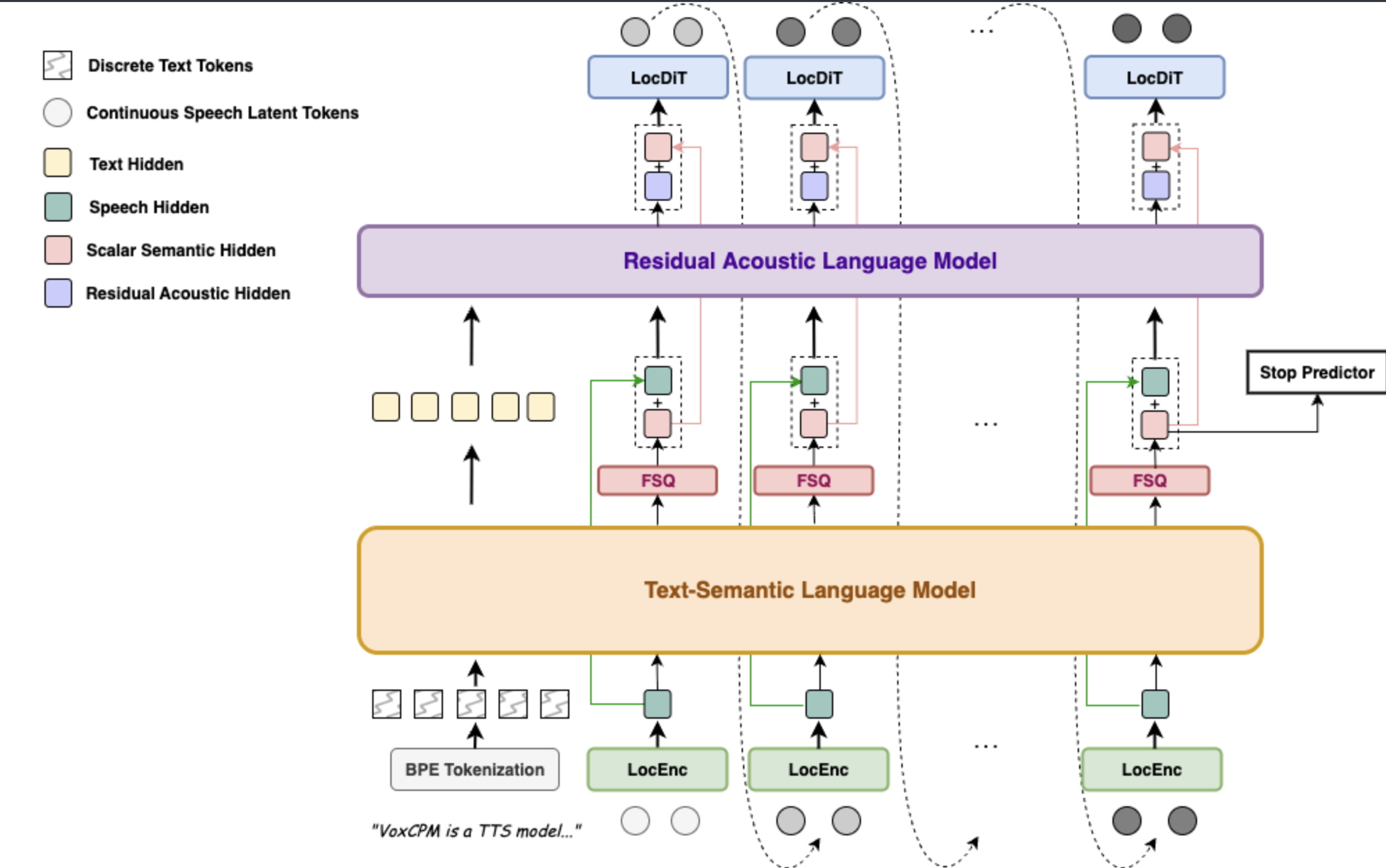
- TADA: A Generative Framework for Speech Modeling via Text-Acoustic Dual Alignment — LLM-based TTS systems typically rely on fixed-frame-rate acoustic tokenization, which produces very long token sequences — a poor fit for sequence modeling at scale. TADA introduces a dual text-acoustic alignment objective that reduces this mismatch, yielding more compact representations without sacrificing zero-shot generation quality. The approach allows LLM-based TTS to scale more efficiently while retaining the expressiveness of token-based synthesis.
- MAEB: Massive Audio Embedding Benchmark — Audio embedding models have been evaluated inconsistently across fragmented benchmarks, making cross-model comparison unreliable. MAEB unifies evaluation across 30 tasks spanning speech, music, environmental sounds, and audio-text reasoning in 100+ languages, covering 50+ models under a common framework. A key finding is that no single model dominates across all tasks, suggesting the field still lacks a general-purpose audio embedding.
- Audio MultiChallenge: A Multi-Turn Evaluation of Spoken Dialogue Systems on Natural Human Interaction — End-to-end spoken dialogue systems are predominantly benchmarked on synthetic speech and single-turn exchanges, which don’t reflect real conversational conditions. Audio MultiChallenge introduces a multi-turn evaluation suite using natural human speech, covering disfluencies, interruptions, and contextual dependencies that arise in practice. This exposes systematic weaknesses in current E2E systems that single-turn synthetic benchmarks consistently miss.
- Soft Clustering Anchors for Self-Supervised Speech Representation Learning in JEPA — Joint Embedding Predictive Architectures (JEPA) are promising for self-supervised speech learning but prone to representation collapse without explicit grounding. GMM-Anchored JEPA addresses this by fitting a Gaussian Mixture Model on log-mel spectrograms once and using the resulting soft cluster assignments as stable anchor targets during training. This prevents collapse without requiring a momentum encoder or a discrete speech tokenizer.
- The Design Space of Tri-Modal Masked Diffusion Models — Most multimodal diffusion models are bimodal and initialised from a pretrained unimodal base, limiting their joint modelling capacity. This paper introduces the first tri-modal masked diffusion model — covering text, image, and audio — pretrained from scratch rather than adapted from a single-modality checkpoint. It systematically explores the architecture and training choices specific to tri-modal pretraining, establishing a new design baseline for joint discrete diffusion.
- LongCat-AudioDiT — Audio diffusion transformer from Meituan targeting long-context audio generation (paper PDF on GitHub; limited metadata available).
LLM Architecture & Training
- Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models | [Code ] — DeepSeek introduces “conditional memory” as a complementary sparsity axis to MoE, implementing learned knowledge lookup as a native transformer primitive.
- GLM-5: from Vibe Coding to Agentic Engineering — Next-generation foundation model targeting agentic, reasoning, and coding capabilities with reduced training and inference costs.
- On Surprising Effectiveness of Masking Updates in Adaptive Optimizers — Shows that randomly masking parameter updates in RMSProp consistently outperforms recent dense adaptive optimizers for LLM training.
- Decoding as Optimisation on the Probability Simplex — Reframes top-k, top-p (nucleus), and best-of-k sampling as instances of a principled regularised optimisation problem, unifying previously ad-hoc decoding choices.
- KV Cache Transform Coding for Compact Storage in LLM Inference — Applies transform coding to KV caches to enable efficient multi-turn reuse without excessive GPU memory consumption.
Other
- Why AI Systems Don’t Learn and What to Do About It — Proposes a cognitive science-inspired architecture with separate systems for observational and active learning, addressing gaps in autonomous AI adaptation.
Also Worth a Look
- A New Framework for Evaluating Voice Agents (EVA) : Evaluation framework from ServiceNow AI for benchmarking voice agents end-to-end across speech understanding, dialogue, and synthesis.
- Did GPT 5.2 Make a Breakthrough Discovery in Theoretical Physics? : Careful analysis of a claim that GPT 5.2 independently derived a result about single-minus gluon amplitudes in particle physics.
- KittenTTS : State-of-the-art TTS model under 25MB — an attempt at extreme model compression for on-device speech synthesis.
- speech2speech_fullduplex : Full-duplex speech-to-speech pipeline with barge-in support and multiple agent personalities in English and Hindi.
- SpeechBrain : Long-established PyTorch speech toolkit covering ASR, TTS, speaker recognition, and more.
- Quantization from the Ground Up : Thorough 6,000-word guide to quantization for LLMs, from fundamentals through to practical compression techniques.
- KV Caching in LLMs, Explained Visually : Clear visual explanation of KV caching mechanics, useful for interviews or onboarding.
- LLM Architecture Gallery : Architecture figures and fact sheets for a large collection of LLMs, updated regularly by Sebastian Raschka.
- LLM Visualization : Interactive 3D visualisation of transformer internals — good for building intuition.
- Deep Dive into LLMs like ChatGPT : General-audience deep dive into LLM training and architecture from first principles.
- MLE Interview 2.0: Research Engineering and Scary Rounds : Detailed 64-minute read on ML research engineer interview rounds at top AI labs.
- ML/Research Engineer Interviews 2025 : First-person account of ML research engineer interviews at Anthropic, DeepMind, Midjourney, Runway, Suno, and others.
- Ollama vs Llama.cpp: Complete Comparison Guide : Beginner-friendly breakdown of the difference between llama.cpp and Ollama for local LLM inference.
- parameter-golf : OpenAI’s challenge to train the smallest LM that fits in 16MB — a fun community exercise in extreme efficiency.
- Learn Claude Code Interactively : 11 interactive modules covering Claude Code from first slash command to building plugins, with terminal simulators and quizzes.
- Claude Code Roadmap : Step-by-step learning roadmap for Claude Code on roadmap.sh.
- Emergent Mind : arXiv research explorer with paper summaries, video overviews, and email digests.
- Introduction to LLM Post-Training Techniques : Slide deck by Maxime Labonne covering SFT, preference alignment, RL, dataset creation, and evaluation.
- Google DeepMind Unified Latents (UL) : Summary of UL, a framework that jointly regularises latents using a diffusion prior and decoder.
- MoonshotAI/Attention-Residuals : Moonshot AI research code for attention residual mechanisms in transformer architectures.
- Essential Machine Learning Equations : Reference guide for key ML equations with working Python implementations.
- aman.ai : Large collection of AI/ML concept guides, from classical algorithms to LLM architectures.
- AI by Hand : Substack by Prof. Tom Yeh covering math, algorithms, and architectures drawn by hand.
- System Design Handbook + Architecture Patterns Playbook : Google Drive folder with system design reference materials.
- NVIDIA PersonaPlex 7B on Apple Silicon: Full-Duplex Speech-to-Speech in Native Swift with MLX On-device speech recognition, synthesis, and understanding for Mac and iOS. Runs locally on Apple Silicon — no cloud, no API keys, no data leaves your device.